
AI infrastructure and deployment
We support on-prem, cloud-native, hybrid, and air-gapped AI deployments based on your security, latency, compliance, and cost requirements.
What you get
Faster, cheaper, and more reliable AI infrastructure

We optimize every watt, token, and millisecond
From expensive and unstable to fast and production-ready
AI infrastructure is not just about buying GPUs. It is about using every GPU efficiently. OneBonsai profiles your full stack, from model architecture and quantization to serving, containers, orchestration, networking, storage, and observability.
EU sovereign AI infrastructure
Keep models, data, and inference fully within EU borders or fully offline. We design and deploy on-prem GPU clusters and air-gapped systems for regulated industries, defenseremm, government, and healthcare. No dependency on US hyperscaler clouds or external APIs. Includes EU-based hardware sourcing, data residency controls, and compliance with NIS2, GDPR, and sector-specific sovereignty requirements.

One stack, every layer
One AI stack for cloud, on-prem, hybrid, and edge
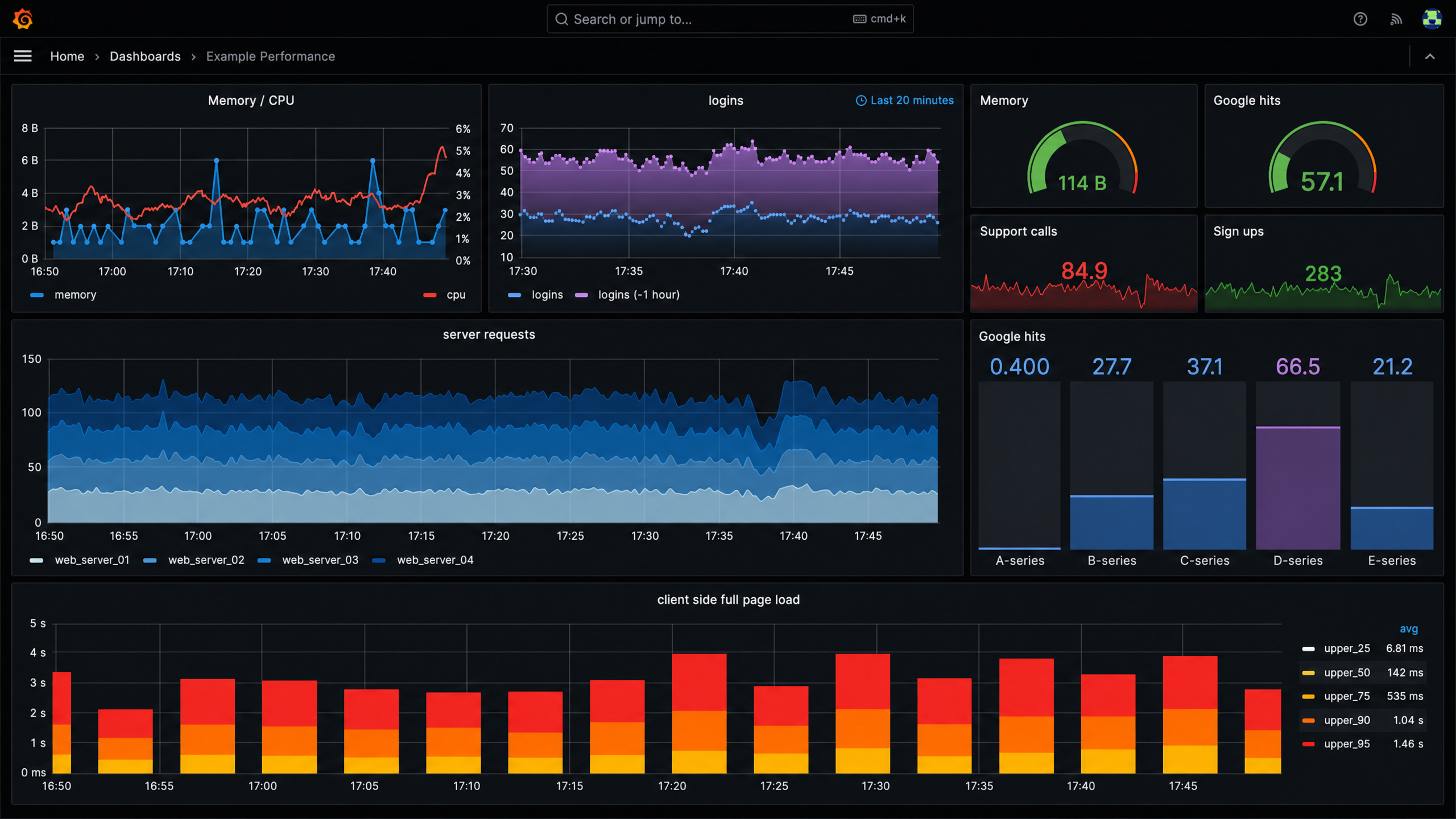
From black box to live AI observability
See exactly how your AI infrastructure performs
We do not guess. We measure. Our dashboards expose GPU, memory, power, temperature, PCIe, network, disk, and model-serving metrics in real time so you can remove bottlenecks and validate improvements before and after optimization.
How to start
Start with an AI infrastructure audit
In one short engagement, we benchmark your current workload, identify bottlenecks, and deliver a practical optimization plan with quick wins and long-term roadmap.
Deliverables