Inference optimization is moving beyond one-token-at-a-time decoding. This article explains speculative decoding, how multi-token prediction (MTP) changes the serving story in vLLM and llama.cpp, and why these newer inference paths matter for real-world performance.
Inference Updates: From Speculative Decoding to MTP in vLLM and llama.cpp
Inference is getting faster, but the interesting part is how it is getting faster.
For a while, one of the most talked-about techniques was speculative decoding: use a small model to guess ahead, then let the larger model verify those guesses. Now the conversation is shifting toward multi-token prediction (MTP), where that “guess ahead” behavior is built much more tightly into the model itself.
This matters because inference optimization is no longer just about raw model quality. It is about latency, throughput, memory efficiency, and operational simplicity. That is exactly why MTP is becoming an important update to watch in stacks like vLLM and llama.cpp.
The Core Idea Behind Speculative Decoding
Most language models generate text one token at a time. After each token, the model has to run another decoding step to produce the next one. That works, but it is slow, because the same expensive process repeats for every token in the response.
Speculative decoding speeds this up by using two models:
- a small draft model that quickly predicts several future tokens
- a larger target model that verifies in parallel whether those predicted tokens can be accepted.
The idea is that some parts of a response are easy to predict. If the draft model can correctly guess a short run of upcoming tokens, the larger model does not need to generate each of them one by one.
Instead, the larger model checks those drafted tokens in parallel in a single forward pass. If they are correct, it can accept multiple tokens at once. If they are only partly correct, it accepts the valid prefix and then continues generation from the first token where it disagrees.
That is what makes speculative decoding useful. The smaller model is not making the final decision. It is only proposing likely next tokens. The larger model is still the one that decides what stays.
This creates a practical tradeoff:
- when the draft model guesses well, generation becomes much faster
- when it guesses poorly, the system gains much less because fewer drafted tokens are accepted
- the main drawback is operational: you now need to host and coordinate two models instead of one
Speculative decoding uses a small model to guess ahead, then lets the main model approve several tokens at once instead of generating each one separately.
That is why speculative decoding became such an important inference optimization. It keeps the same autoregressive generation process, but reduces how often the large model has to do the expensive part on its own.
Speculative Decoding Example
Imagine the main model has already generated the phrase “Actions speak”. Many people will immediately recognize how that expression usually continues: “louder than words.” Because that continuation is so familiar, a much smaller model has a good chance of predicting the same next few tokens as the larger model.
That is exactly where speculative decoding becomes useful. Instead of forcing the main model to generate each of those obvious next tokens one at a time, a smaller draft model can try to predict several of them in advance. Starting from the same prompt, the draft model might generate the next four tokens ahead of time. Since that draft model is much smaller, it can produce those guesses far more quickly than the full target model.
![Speculative Decoding Gemma 4.[1]](http://a.storyblok.com/f/290559959006706/272873/5bcc073547/speculative_decoding.png)
Why This Matters
Most LLM inference still works in a simple loop: generate one token, run the model again, generate the next token, and repeat.
That process is reliable, but it is also expensive. Every extra decoding step adds latency. When you are serving real applications, that cost shows up as:
- slower first-token and end-to-end response times
- lower throughput under concurrency
- more infrastructure pressure
- harder cost control at production scale
That is why inference research has become so focused on ways to reduce the amount of expensive step-by-step decoding without changing the final behavior too much.
Where Classic Speculative Decoding Gets Hard
The original appeal of speculative decoding is obvious, but the deployment tradeoff is also obvious: you are now hosting two models instead of one.
That creates several practical drawbacks:
- extra memory footprint
- more complicated serving pipelines
- draft-model selection and tuning overhead
- weaker gains when the draft model is poorly matched to the target model
There is also an important nuance here. A common shorthand is that if the small model predicts garbage, you get garbage output. That is not quite the right way to frame it.
In properly implemented speculative decoding, the larger model still verifies drafted tokens before they are accepted. So a weak draft model usually does not mean the final output automatically becomes worse. What it usually means is:
- fewer accepted draft tokens
- more wasted speculative work
- smaller performance gains
- more overhead for the same result
So the real issue is often efficiency and complexity, not just output quality.
From Speculative Decoding to “Speculative Speculative Decoding”
This is where the next update comes in.
What some people loosely call “speculative speculative decoding” is the move toward native, single-model speculation. Instead of pairing a large model with a separate helper model, the model itself is trained to predict multiple future tokens.
That is the role of multi-token prediction (MTP).
You can think of MTP as a more integrated version of the same idea:
Instead of bolting a drafter onto the side, the model learns to draft from within its own architecture.
That makes MTP feel like self-speculative decoding. It keeps the performance logic of speculation, but with less duplicated infrastructure.
MTP
Instead of relying on a separate draft model that sits beside the target model, MTP brings that drafting behavior into the model’s own inference path. The model can propose several likely next tokens, and the target path still decides which of those tokens should be accepted.
That changes the serving story in a few important ways:
- it reduces or removes the need to host a separate drafter
- it cuts down serving complexity and coordination overhead
- it aligns speculative behavior more closely with the main model
- it can make speedups more predictable on supported model families
The acceptance logic does not change. If the proposed tokens are correct, multiple tokens can be accepted at once. If only part of the proposal is correct, the valid prefix is accepted and generation continues from the first point of disagreement.
That is what makes MTP important. It is not a completely different idea from speculative decoding. It is a cleaner way to achieve the same kind of acceleration, with less extra infrastructure around it.
MTP makes speculative decoding feel native to the model instead of dependent on a separate helper model.
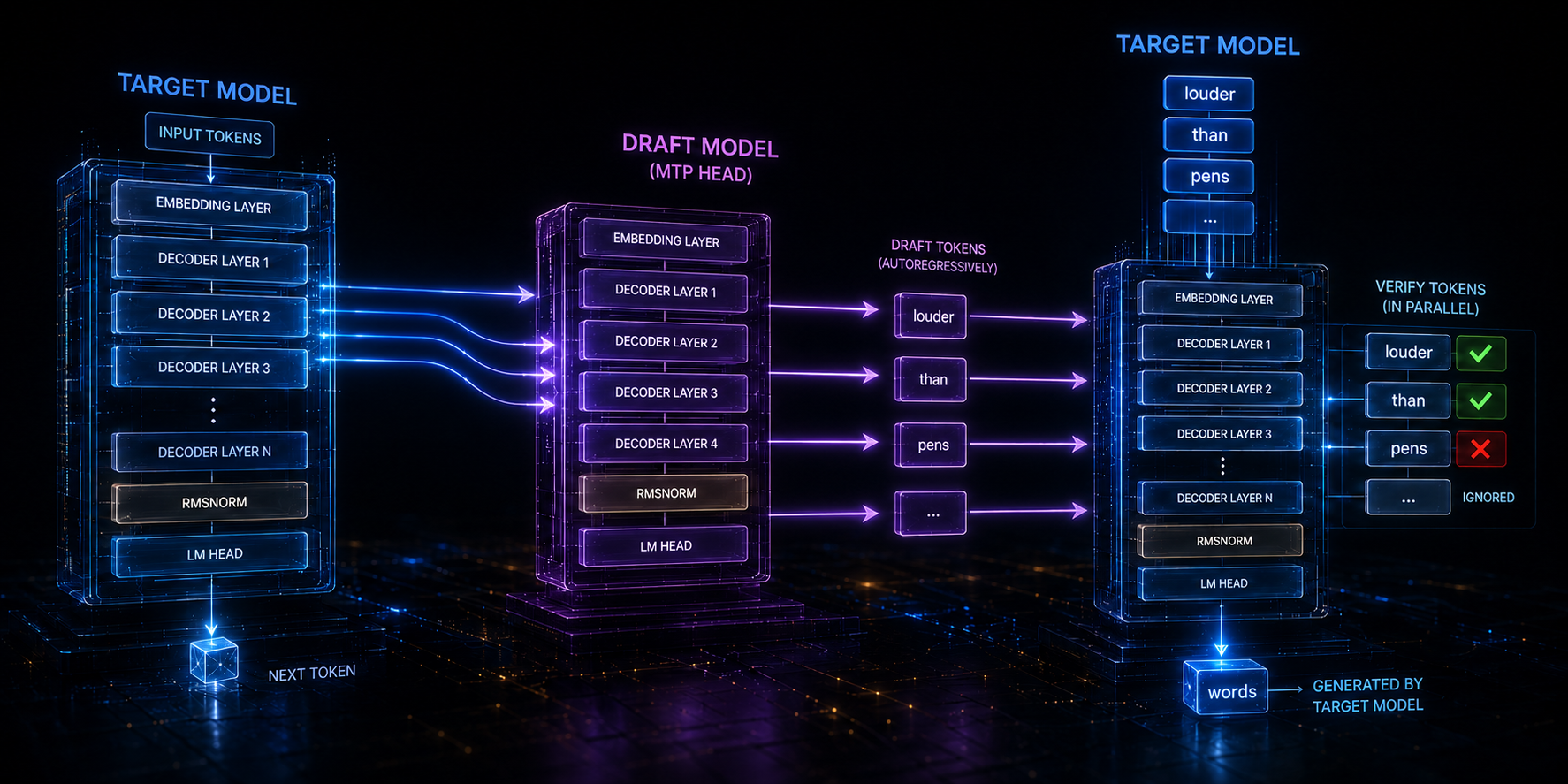
MTP Example
A simple example makes MTP much easier to understand.
Imagine the target model has already generated the phrase “Actions speak”. From there, the system tries to move ahead faster by drafting several likely next tokens. In this example, the draft path proposes:
- louder
- than
- pens
Those draft tokens are produced autoregressively, meaning the draft path still generates them one after another. The difference is that it can do this much more cheaply than the full target model.
![Multi-token prediction architecture with draft model and target model verification. [1]](https://a.storyblok.com/f/290559959006706/149151/eb97661bcb/mtp_1.jpeg)
At that point, the target model does not need to generate each of those tokens one by one from scratch. Instead, it verifies the drafted sequence in parallel during its forward pass.
That verification step is what makes MTP useful. If the drafted tokens are correct, the model can accept several of them at once. If they are only partly correct, it accepts the valid prefix and stops at the first mismatch.
In this example, the target model agrees with “louder” and “than”, but rejects “pens.” Once that rejection happens, the remaining drafted tokens after it are discarded as well.
![Accepted and rejected draft tokens during multi-token prediction verification. [1]](http://a.storyblok.com/f/290559959006706/124143/136703e188/mtp_2.jpeg)
Because the target model has already done a forward pass, it can immediately provide its own replacement for the rejected token. So instead of keeping “pens,” it generates “words.”
That means the selected continuation becomes:
- louder
- than
- words
So the sequence moves from:
Actions speak
to:
Actions speak louder than words
![Speculative decoding process showing how selected tokens become the next model input [1]](http://a.storyblok.com/f/290559959006706/89553/123dfa055d/mtp3.jpeg)
This is the core advantage of MTP. The draft path can propose multiple future tokens quickly, and the target model can verify all of them together instead of spending a separate decoding step on each one. The model is still autoregressive, but it can move through easy token sequences much more efficiently.
MTP speeds up generation by drafting multiple likely tokens ahead of time, then letting the target model accept the correct ones and replace the first token it rejects.
DeepSeek-V3 Helped Push MTP Into The Spotlight
DeepSeek-V3 is one of the main models that pushed MTP into the mainstream open-model discussion.
A careful way to say it is that DeepSeek-V3 helped popularize MTP as a practical inference topic, especially for people watching open model architecture choices closely. Its technical report made multi-token prediction hard to ignore as a serious optimization direction rather than a niche trick.
That is why so many recent inference conversations now connect speculative decoding, native drafting, and MTP in the same breath.
Gemma 4 And Nemotron Show The Pattern Is Spreading
This is no longer a one-model story.
Gemma 4 includes an MTP-based inference path, and NVIDIA’s Nemotron Super 120B A12B is another example of a model family that supports native speculative-style acceleration. Qwen 3.6 now belongs in that conversation too, especially as MTP-enabled artifacts and runtime support start showing up around local and production inference workflows.
That matters because it shows MTP is becoming a real serving consideration across modern model ecosystems, not just an isolated research experiment.
At the same time, there is an important caveat teams should understand early: MTP tends to be more compelling on dense models than on MoE models.
Why? Because expert routing can make speculative acceptance less predictable. In practice, that means you may see weaker gains on MoE systems, especially in low-batch or latency-sensitive conditions. So while MTP support on MoE models is real, the business outcome is not always as dramatic as the headline suggests.
That is also part of why Qwen 3.6 is a useful example. It helps show both sides of the story: MTP is clearly spreading, but the size of the speedup still depends heavily on the model architecture and serving setup.
What Changed In vLLM
As of May 20, 2026, vLLM documents MTP as a supported speculative decoding method for compatible models.
That is important because vLLM has become a default serving layer for many production inference teams. When MTP is exposed directly in a runtime like this, it moves from “interesting architecture detail” to “something operators can actually benchmark and deploy.”
In practical terms, vLLM lets teams treat MTP as part of the serving configuration rather than an entirely separate orchestration problem.
That is the shift:
- classic speculative decoding asks, “Which draft model should I pair with my target model?”
- MTP asks, “Does my target model already know how to draft for itself?”
What Changed In Llama.cpp
Llama.cpp matters because it is where many teams, researchers, and edge deployments first inference locally.
As of May 20, 2026, the official speculative decoding documentation in llama.cpp includes a draft-mtp mode. That is a meaningful signal: native MTP-style acceleration is no longer just a server-side conversation. It is becoming part of local and edge inference workflows too.
This is especially relevant for teams that prototype on llama.cpp and then scale into larger serving stacks later. It shortens the gap between experimentation and deployment.
Real-World Optimization In Practice
Getting faster inference is not just about enabling one feature. It is about measuring the full serving path and understanding where the bottlenecks actually are.
For this article, we recorded a real OneBonsai speed comparison using:
- Model: unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q4_K_XL
- Inference engine: llama.cpp for edge deployment
- Hardware: NVIDIA L40S vGPU
In our benchmark, the baseline configuration achieved approximately 35.8 tokens per second, while the OneBonsai-optimized configuration achieved approximately 84.2 tokens per second, representing an observed 2.35× throughput improvement.
Importantly, this increase was achieved while maintaining comparable output quality and operating within the same memory budget. As with any inference benchmark, measured throughput can fluctuate slightly between runs due to serving conditions, system load, and runtime scheduling behavior. The reported values should therefore be viewed as representative results from this test environment rather than guaranteed performance figures.
This benchmark is not meant to claim that MTP alone creates the full improvement. The result comes from the complete optimization path: model artifact choice, runtime configuration, serving setup, prompt behavior, decoding settings, and hardware-aware tuning.
That distinction matters. In real deployments, performance rarely improves because of a single switch. It improves when the full inference stack is configured correctly.
For production teams, the practical question is not only:
Does this model support MTP?
The better question is:
Which combination of model, runtime, artifact, hardware, and serving configuration gives the best result for our workload?
That is where benchmarking becomes essential. A feature like MTP can be valuable, but its real impact depends on how it is deployed, measured, and tuned.
Where OneBonsai Fits In
This is where OneBonsai helps teams move from theory to production evidence.
Instead of assuming that a new optimization will automatically improve deployment performance, we test the full inference pipeline under realistic conditions. That includes model selection, artifact validation, runtime configuration, quantization, fine-tuning, GPU setup, latency measurement, and throughput benchmarking.
In practice, this means helping teams answer questions such as:
- Which runtime performs best for this workload?
- Does the selected model artifact preserve the required optimization features?
- How much speedup is visible in real usage, not just synthetic benchmarks?
- What tradeoffs appear between latency, throughput, memory use, and output quality?
- Is the optimization worth adopting in production?
In this benchmark, the OneBonsai-optimized setup demonstrates how much performance can change when the serving stack is tuned carefully. That is the real lesson: modern AI deployment is not only about choosing a model, but about engineering the system around it.
References
- [1]References: Google Gemma. “Gemma 4 MTP technical explainer.” X post, 2026. https://x.com/googlegemma/status/2051694045869879749
- [2]Google. “Accelerating Gemma 4: faster inference with multi-token prediction drafters.” The Keyword, May 5, 2026. https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
- [3]Google AI for Developers. “Gemma 4 Multi-Token Prediction (MTP) using Hugging Face Transformers.” Last updated May 5, 2026. https://ai.google.dev/gemma/docs/mtp/mtp