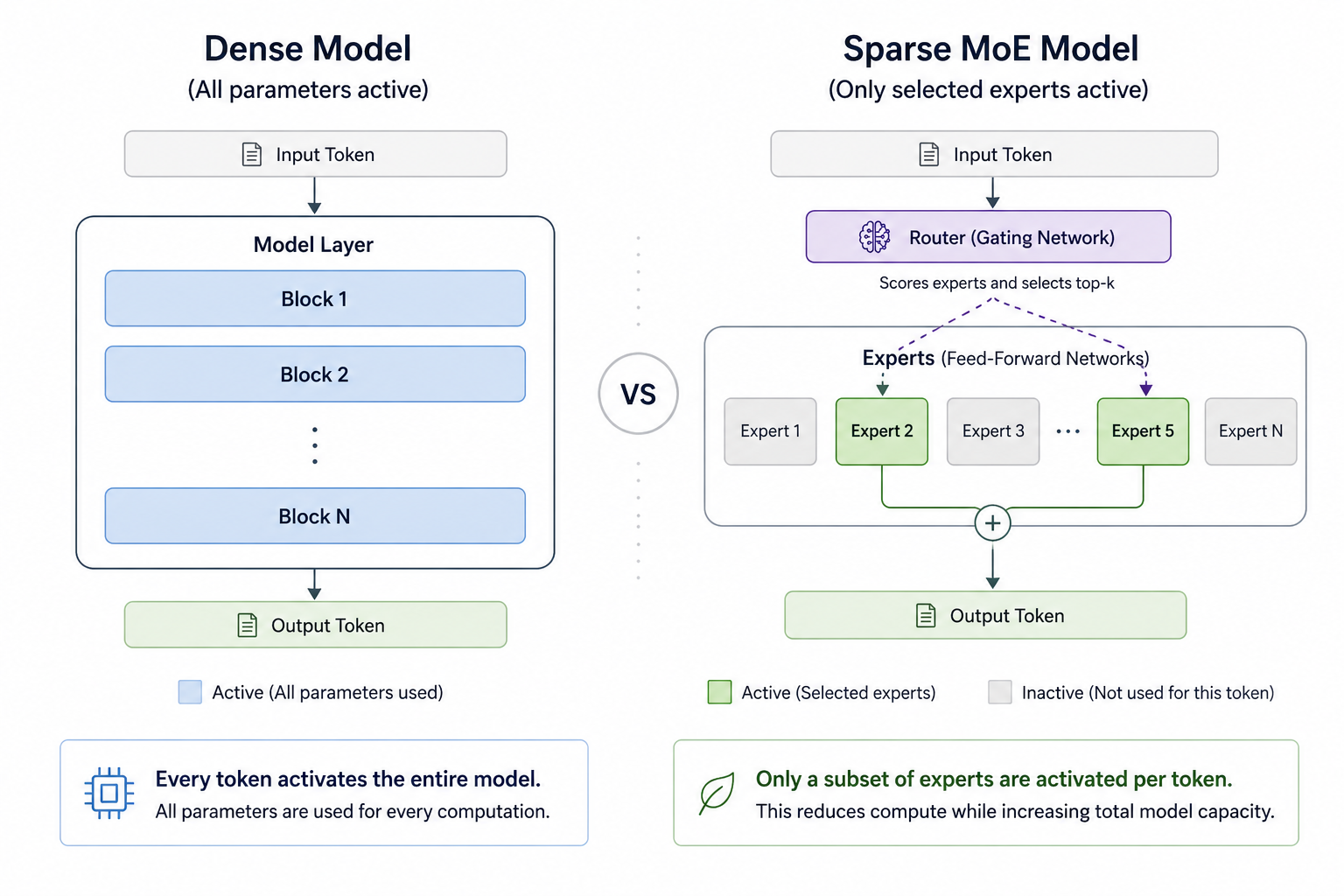
For years, AI progress was driven by building larger dense models that used all parameters for every token. Mixture-of-Experts changes this by using sparse activation: the model may contain many experts, but only the most relevant experts are activated for each token. This makes it possible to scale model capacity without scaling active compute at the same rate. This post explains what MoE is, how dense and sparse MoE differ, why routing and load balancing matter, how newer approaches like DeepSeekMoE improve expert specialization, and why these architecture choices directly affect cost, latency, and enterprise deployment strategy.
Why Mixture-of-Experts Models Are Changing How Frontier AI Scales
1. Introduction: Bigger used to mean better
Until recently, the industry standard for building smarter AI was straightforward: build bigger dense models.
Dense models use all of their parameters to generate every token. For today’s most capable models, this can mean activating hundreds of billions of parameters for each step of generation. While this approach has produced impressive results, it also requires enormous compute power, memory, and energy.
That makes dense scaling difficult to sustain.
Mixture-of-Experts, or MoE, offers a different path. Instead of using the entire model computation for every token, MoE models activate only the most relevant expert blocks. This makes it possible to increase total model capacity while keeping the amount of active compute much smaller.
The key shift is simple:
Dense models scale by using everything.
Sparse MoE models scale by learning what to use.
2. Dense vs sparse MoE
Not every MoE model is sparse.
A dense MoE can combine many experts for every input, which means all or most experts contribute to the result. This can increase model capacity, but it does not solve the main compute problem because too much of the model is still active.
Sparse MoE is the version most relevant for modern large language models.
In sparse MoE, only a small number of experts are selected for each token. The model can have many experts in total, but the router activates only the top expert or top few experts during each forward pass.
That distinction matters:
- Dense model: all parameters are used for every token
- Dense MoE: tokens are distributed to all experts.
- Sparse MoE: tokens are distributed to selected experts only.
This is why sparse MoE is so important for frontier AI. It separates total model capacity from active compute.
A model can be very large in total parameter count, while still using a much smaller number of active parameters per token.
3. What does Mixture-of-Experts mean?
The name “Mixture-of-Experts” comes from the idea that a model can contain multiple specialized components, called experts.
A simple analogy is a company meeting:
- In a dense model, every department joins every meeting.
- In a sparse MoE model, only the most relevant specialists are invited.
In transformer-based language models, an expert is usually a feed-forward network block inside the model. Instead of having one feed-forward block in a layer, an MoE layer has multiple expert blocks.
A router, sometimes called a gating network, decides which expert or experts should handle each token.
The router is therefore one of the most important parts of the architecture. It controls which knowledge is activated, how compute is distributed, and how efficiently the model uses its expert capacity.
4. How MoE works during inference
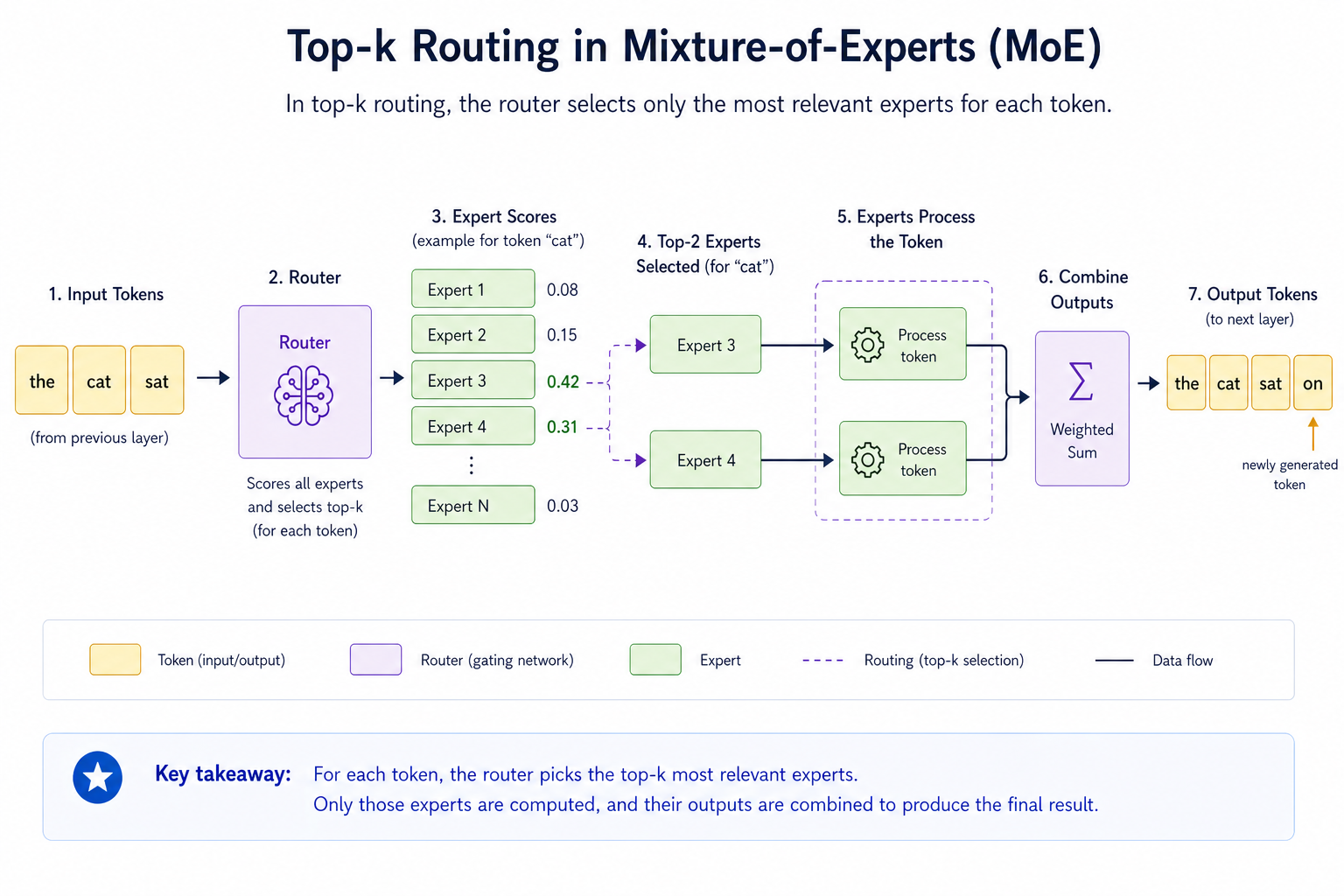
At inference time, the process usually looks like this:
- A token enters an MoE layer.
- The router scores the available experts.
- The router selects the top expert or top few experts.
- Only those selected experts process the token.
- Their outputs are combined and passed to the next layer.
This is often called top-k routing.
For example, in top-2 routing, the router selects the two most relevant experts for a token. The model may contain many experts, but only two are activated for that token.
That is the key efficiency advantage.
The full model may contain hundreds of billions of parameters, but each token only uses a much smaller active subset.
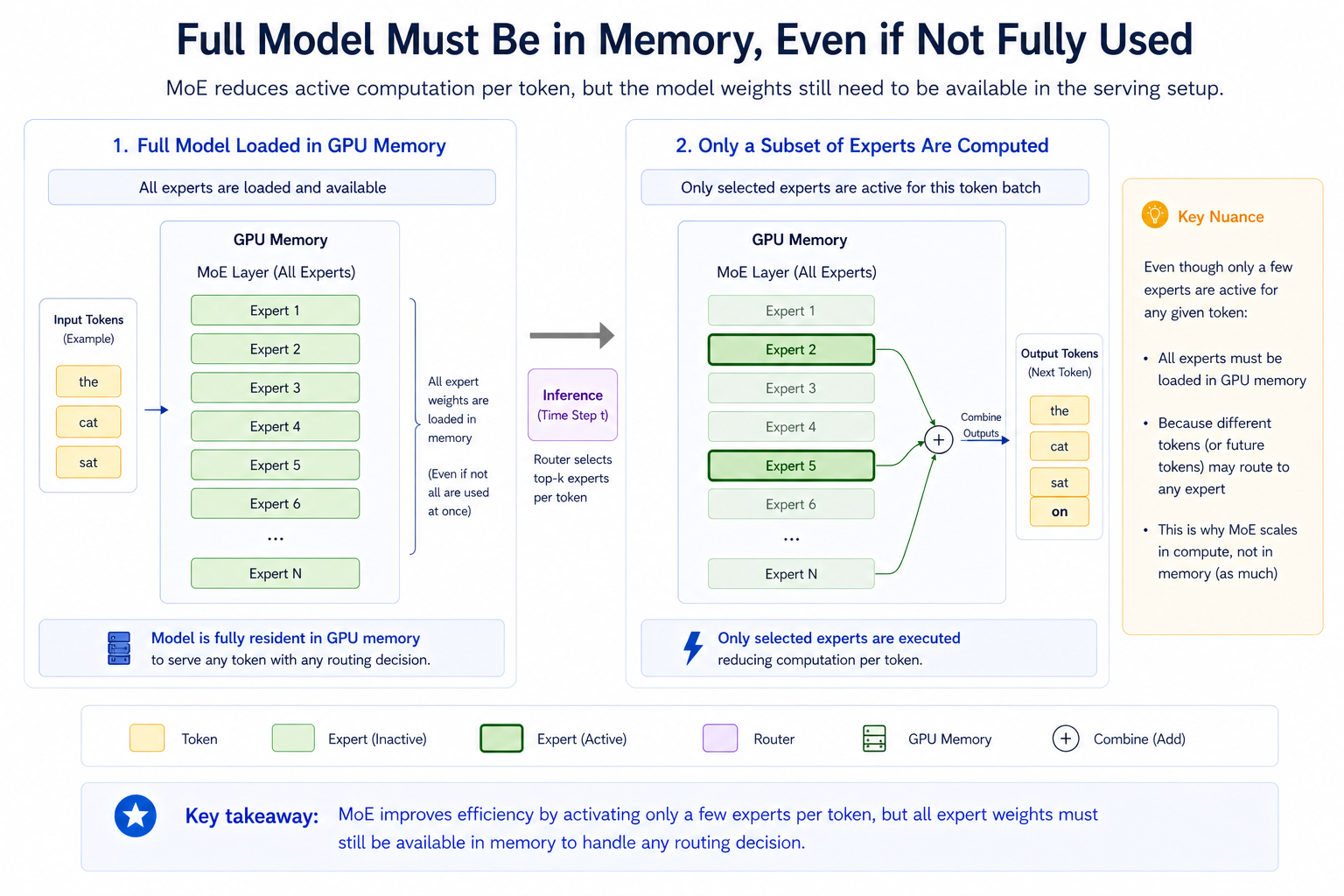
However, there is an important deployment detail: the inactive experts do not disappear. The model weights still need to be available in memory somewhere in the serving setup. Depending on the deployment, this may mean loading the full model across one or more GPUs, or sharding experts across multiple devices.
So MoE mainly reduces active computation per token.
It does not automatically remove the memory requirement of storing the model.
This distinction is important when planning real deployments.
5. Why MoE can be cheaper to run
MoE changes the economics of large models because total parameters and active parameters are no longer the same thing.
A dense model uses all parameters for every token.
A sparse MoE model may have a very large total parameter count, but only a fraction of those parameters are active per token.
This can lead to:
- Lower compute per generated token
- Better performance per watt
- Better performance per dollar
- More scalable inference
- Higher model capacity without a proportional increase in active compute
However, MoE is not automatically cheaper in every situation.
The benefit depends on how well the model and serving infrastructure are implemented. MoE introduces extra complexity around:
- routing
- batching
- memory distribution
- expert parallelism
- communication between GPUs
- load balancing
If the system is poorly balanced, one popular expert can become a bottleneck while other experts remain underused. In that case, the theoretical efficiency of MoE may not translate into real production efficiency.
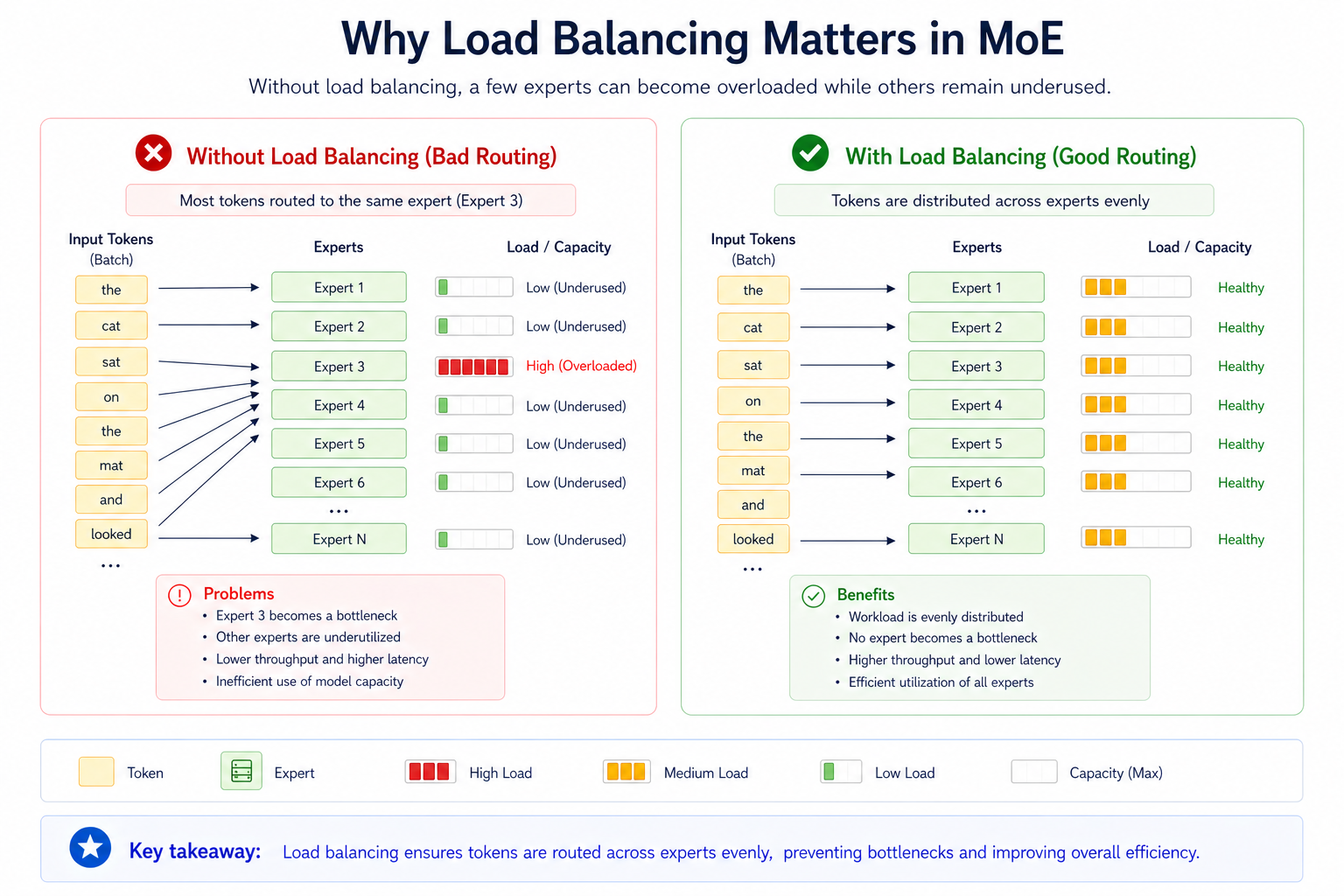
6. Routing, expert capacity, and load balancing
Routing is what makes MoE powerful, but it is also what makes MoE difficult.
During training, the router learns which experts should process which tokens. If left unmanaged, the router can start choosing the same experts too often. Those experts then receive more training updates, become stronger, and are chosen even more often.
This creates a feedback loop.
Some experts learn too much because they are selected frequently.
Other experts learn too little because they are rarely selected.
This is often called expert imbalance or routing collapse.
To reduce this problem, MoE systems use load balancing techniques.
Common mechanisms include:
Top-k routing
Mentioned before, the router selects the top k experts for each token. In top-1 routing, one expert is selected. In top-2 routing, two experts are selected.
Expert capacity
Each expert can only process a limited number of tokens in a batch. This prevents one expert from receiving too many tokens while others remain idle.
Token choice routing
Tokens choose their preferred experts based on router scores. This is common in top-k routing, but it can create imbalance if too many tokens choose the same expert.
Auxiliary load-balancing loss
During training, an additional loss term encourages tokens to be distributed more evenly across experts. This helps prevent the router from overusing only a small subset of experts.
These techniques are important because MoE efficiency depends on more than sparse activation. It also depends on using the expert pool well.
A large number of experts does not help if the router only uses a few of them.
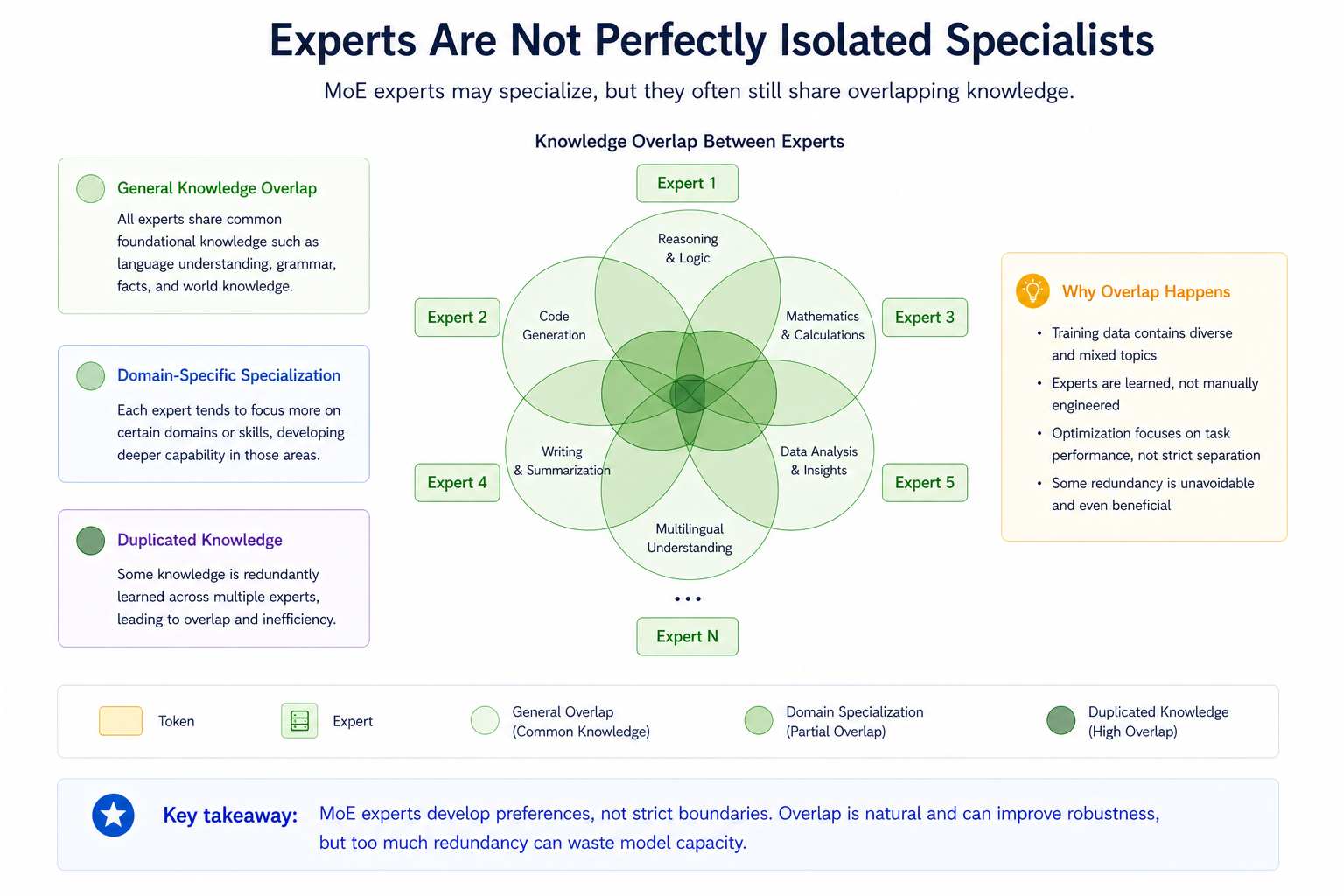
7. What experts actually learn
It is tempting to imagine that each expert becomes a perfectly isolated specialist.
For example:
- one expert for math
- one expert for coding
- one expert for language
- one expert for visual reasoning
In practice, experts are not always that cleanly separated.
Many experts still learn broad general knowledge. Some knowledge is duplicated across experts. The router may also send similar tokens to different experts depending on training dynamics.
This creates an important limitation:
MoE increases capacity, but it does not automatically produce perfectly modular intelligence.
The router is critical because it decides which knowledge is available for each token. If the router selects the wrong expert, useful knowledge in other experts may be ignored.
This is one reason why modern MoE research focuses not only on having more experts, but also on improving how experts specialize and how routing decisions are made.> text
8. From older MoE to newer MoE designs
Earlier MoE models often used a smaller number of large experts.
This worked, but it had limitations:
- Experts could become too broad
- Some experts could be overused
- Some experts could be underused
- Knowledge could be duplicated
- Routing could become inefficient
- Load balancing could interfere with expert specialization
Newer MoE designs try to solve these problems with more refined expert structures.
The goal is no longer just to add experts.
The goal is to make expert usage more precise.
9. DeepSeekMoE and fine-grained expert segmentation
DeepSeekMoE introduced an important idea: fine-grained expert segmentation.
Instead of using a few large experts, the model can use many smaller experts. This gives the router more flexibility. Rather than choosing between a small number of broad experts, it can combine smaller pieces of expertise more precisely.
This helps improve expert specialization and parameter efficiency.
DeepSeekMoE also uses shared experts. These are experts that help capture common knowledge that many tokens need. This reduces the need for every routed expert to relearn the same general information.
The result is a more efficient expert system:
- shared experts handle common knowledge
- routed experts handle more specific knowledge
- fine-grained experts allow more flexible combinations
- expert specialization becomes more targeted
This is an important evolution of MoE. It recognizes that not all knowledge should be routed in the same way.
Some knowledge is general and should be available broadly.
Some knowledge is specific and should be handled by selected experts.
10. Mixture of many experts
As MoE evolves, the direction is clear: more experts, smaller experts, and more precise routing.
This could eventually lead to systems with a very large number of experts, where the model behaves less like one giant network and more like a dynamic collection of specialized modules.
The challenge is making the router good enough to choose the right experts reliably.
More experts only help if the system can route tokens effectively, balance the load, and avoid unnecessary duplication.
In other words, the future of MoE is not just about having more experts.
It is about better expert selection.
11. Lifelong learning and modular updates
MoE also raises interesting possibilities for lifelong learning.
In theory, if parts of a model are more modular, some experts could be frozen while others are updated or retrained. This could make it easier to adapt a model to new domains without retraining the entire network.
However, this introduces a new challenge.
If experts change, the router must also learn when to use them.
Updating experts without updating routing could make the system worse. The model may contain the right knowledge, but fail to activate it at the right time.
So lifelong learning with MoE is promising, but it depends heavily on router adaptation.
A modular model is only useful if the routing system knows how to use the modules.
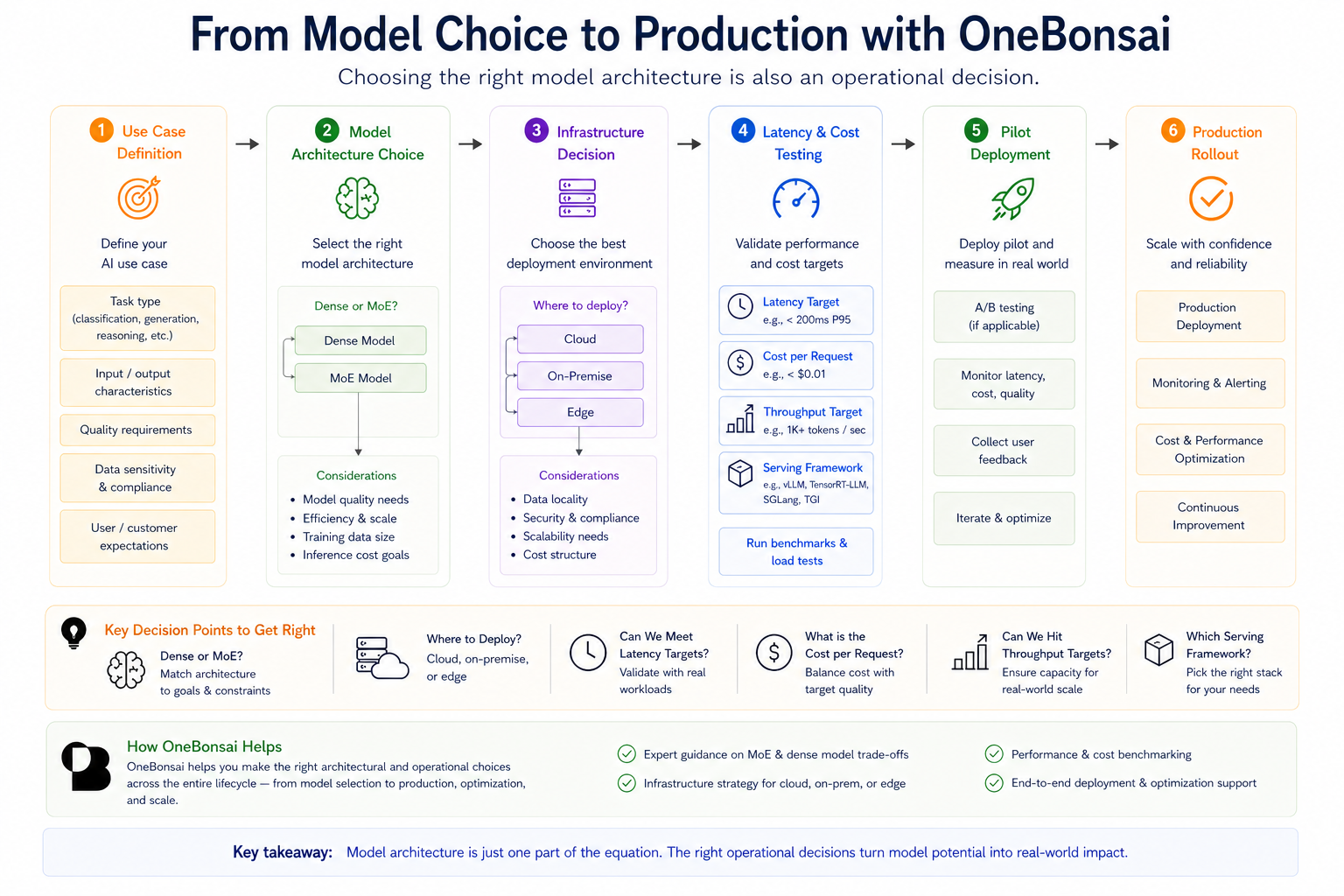
12. Why this matters for enterprise AI
MoE is not only a research trend. It directly affects real-world deployment decisions.
For companies deploying AI systems, architecture choices influence:
- cost per request
- latency
- throughput
- GPU memory requirements
- infrastructure complexity
- serving framework choice
- scaling strategy
This is why choosing between dense and MoE models is not just a model-quality decision. It is an operational decision.
A sparse MoE model may reduce active compute per token, but the full model still needs to be stored and served efficiently. If experts are spread across multiple GPUs, the deployment must handle communication, routing, batching, and load balancing well.
That is why benchmark scores are not enough.
Teams also need to ask:
- How fast does the model need to respond?
- How many users need to be served at once?
- What is the acceptable cost per request?
- How much GPU memory is available?
- Should the model run in the cloud, on-premise, or at the edge?
- Which serving framework best fits the workload?
- Does the infrastructure support efficient routing and batching?
- Is the expected traffic pattern stable enough for efficient expert utilization?
At OneBonsai, this connects directly to helping organizations move from AI interest to practical AI adoption. Through workshops, readiness assessments, assistant pilots, and operational consulting, OneBonsai helps teams identify where AI can create value, evaluate feasibility, and define practical next steps for implementation.
For MoE and other advanced model architectures, that means helping customers match architecture choices to cost, latency, throughput, and operational goals.
The right model is not always the biggest model.
It is the model that delivers the right performance within the right operational constraints.
13. How OneBonsai can help
For organizations exploring large language models, the architecture choice is only one part of the decision.
OneBonsai can help teams evaluate questions such as:
- Should we use a dense model or a sparse MoE model?
- What are the cost and latency tradeoffs for our use case?
- Can our current infrastructure support the selected model?
- Should we use a managed cloud model, self-hosted model, or hybrid setup?
- How do we test model performance under realistic user traffic?
- How do we estimate cost per request before production?
- How do we design pilots that prove business value before scaling?
This is especially important for companies moving beyond experimentation.
A model that performs well in a demo may behave very differently in production. Real workloads introduce constraints around latency, concurrency, data access, security, reliability, and cost control.
OneBonsai helps bridge that gap by translating AI architecture choices into practical deployment decisions.
14. Conclusion: Scaling is becoming selective
The next phase of AI scaling is not just about making models bigger.
It is about making models smarter in how they use their own capacity.
Dense models use everything all the time. Sparse MoE models use selected parts of the model when they are needed.
That shift matters because it changes how we think about capability, efficiency, and deployment.
Mixture-of-Experts models show that the future of frontier AI may not be defined by the total number of parameters alone, but by how intelligently those parameters are activated.
The real breakthrough is not just more knowledge.
It is better routing.