Keeping models, data, and inference fully within EU borders is no longer a compliance checkbox - it's a competitive advantage. Here's what it takes, and how to get there.
What EU AI Sovereignty Actually Requires
More EU organizations - in healthcare, defense, government, and other regulated sectors - are asking the same question: can we run AI without sending data or model weights outside our own jurisdiction, or outside our own network entirely?
The answer is yes, and the path to get there is more mature than most teams realize. Open-weight models, modern inference stacks, and on-prem GPU hardware have closed most of the performance gap that used to make hosted APIs the default choice. What is left is mostly an infrastructure and integration question - which is exactly the part that can be engineered well.
Here is what EU sovereignty actually involves, why it is worth building properly rather than approximating, and how OneBonsai helps organizations get there.

What “sovereign” needs to actually mean
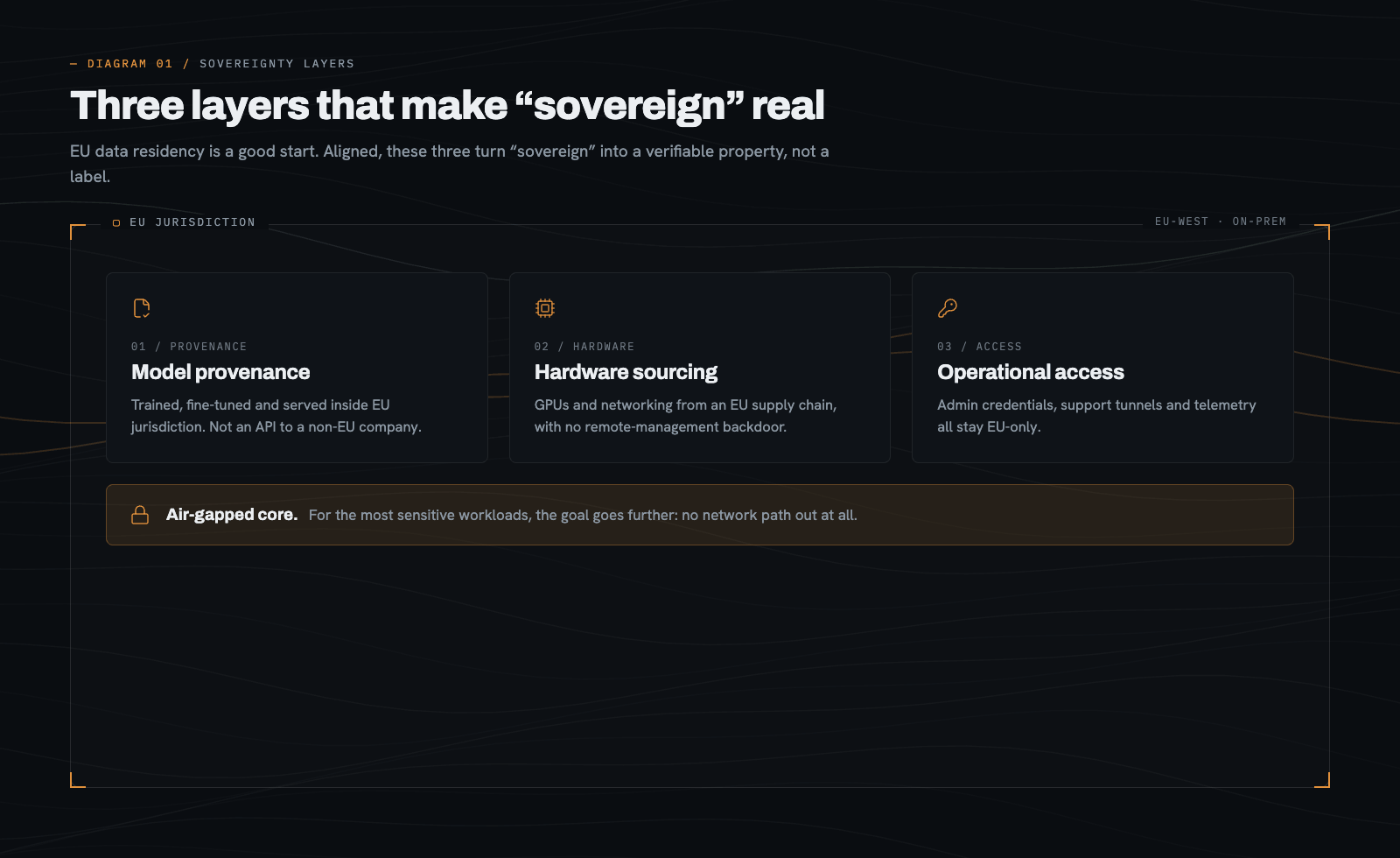
EU data residency, picking a Frankfurt or Amsterdam region, is a good starting point, but it is only part of the picture. The questions that really determine how sovereign a deployment is sit a layer deeper:
Model provenance: Is the model trained, fine-tuned, and served entirely within EU jurisdiction, or accessed via an API from a non-EU company?
Hardware sourcing: Where do the GPUs and networking equipment come from, and who can remotely manage them?
Operational access: Who holds admin credentials, support tunnels, or telemetry access into the stack?
Getting all three aligned, EU jurisdiction, EU-controlled hardware, and EU-only operational access, is what makes “sovereign” a real, verifiable property instead of a marketing label. And for the most sensitive workloads, the goal goes further still: a fully air-gapped system with no network path out at all.
Why this is the right direction, not just a compliance burden
It is easy to frame sovereignty purely in terms of regulation - NIS2’s expanded scope and incident reporting duties, GDPR’s data residency intent, sector rules in healthcare and defense, and DORA for financial services. All of that is real and growing.
But the more interesting shift is that sovereignty has become a genuine engineering and business advantage, not just a box to check.

Full control over performance and cost.
On-prem inference removes the unpredictability of third-party rate limits, pricing changes, and shared-tenancy latency. You tune the stack for your workload.
Stronger trust with regulators, partners, and end users.
Being able to draw a complete diagram of where data and models live - and show that nothing leaves the building - is a strong position in procurement conversations, especially in defense, government, and healthcare.
Future-proofing against regulatory change.
Infrastructure built for genuine sovereignty today can absorb new compliance requirements tomorrow, instead of needing to be rearchitected each time a rule shifts.
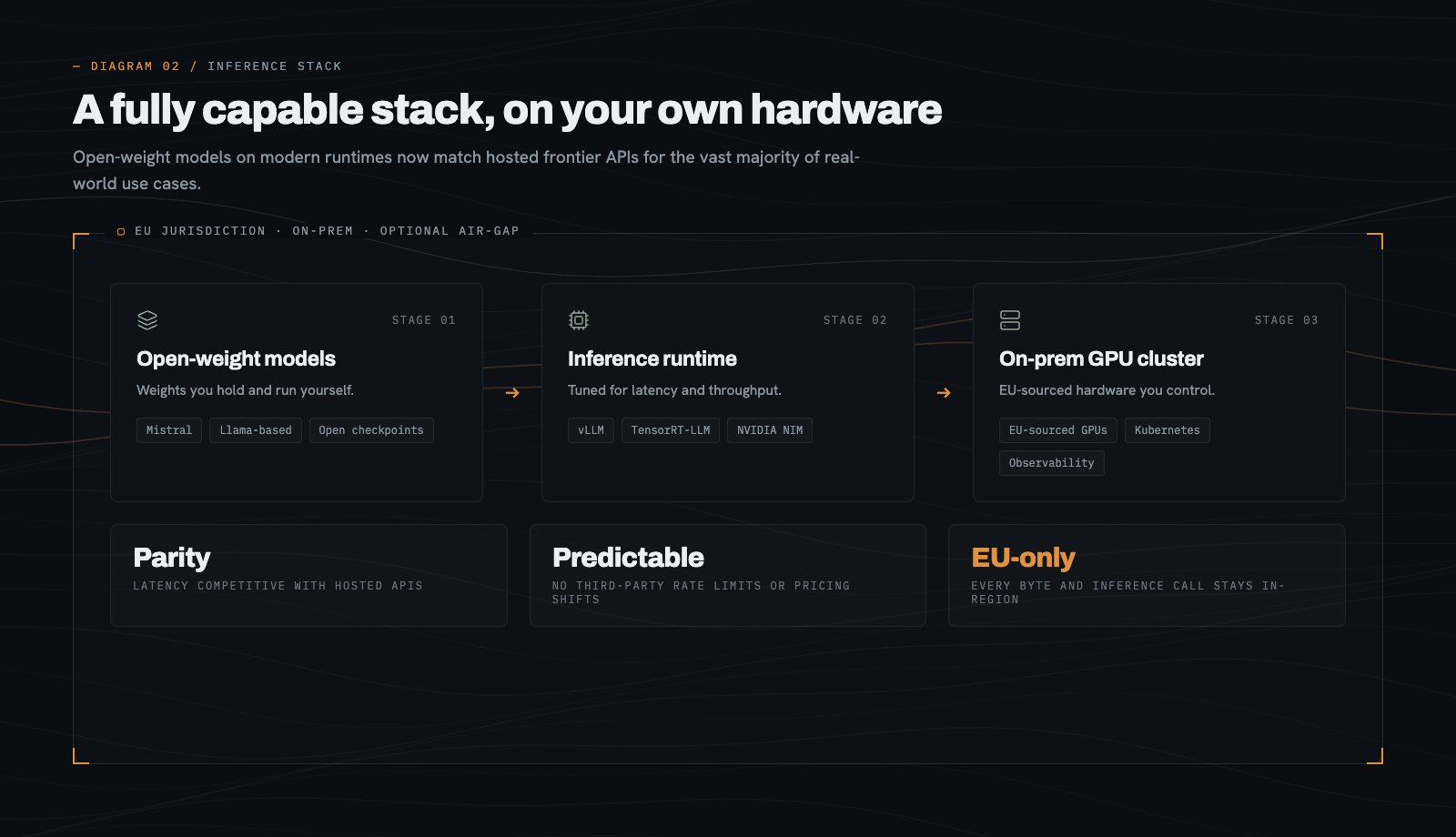
No loss of capability.
Open-weight models such as Mistral, Llama-based models, and others, running on stacks like vLLM, TensorRT-LLM, or NVIDIA NIM, now deliver latency and throughput that is competitive with hosted frontier APIs for the vast majority of real-world use cases.
In other words, sovereign infrastructure is not a slower, smaller version of the cloud. Done well, it is a fully capable AI platform that also satisfies the strictest data and jurisdiction requirements in Europe.
How OneBonsai helps you get there
This is the core of what we do: design and deploy AI infrastructure that stays fully within EU borders, or fully offline, without compromising on capability.
We build on-prem GPU clusters and air-gapped systems for regulated industries, defense, government, and healthcare workloads.
We support EU-based hardware sourcing, so the supply chain itself - not just the data center region - meets sovereignty requirements.
We design data residency controls and architecture around GDPR, NIS2, and sector-specific rules from day one, instead of retrofitting compliance later.
We deploy modern inference and orchestration stacks, including vLLM, TensorRT-LLM, NVIDIA NIM, and Kubernetes-based deployment, tuned for cost, latency, and throughput on your own hardware.
We also support the full lifecycle, from hardware procurement and deployment through observability and ongoing optimization, so sovereignty considerations are addressed at every stage rather than only at the data layer.
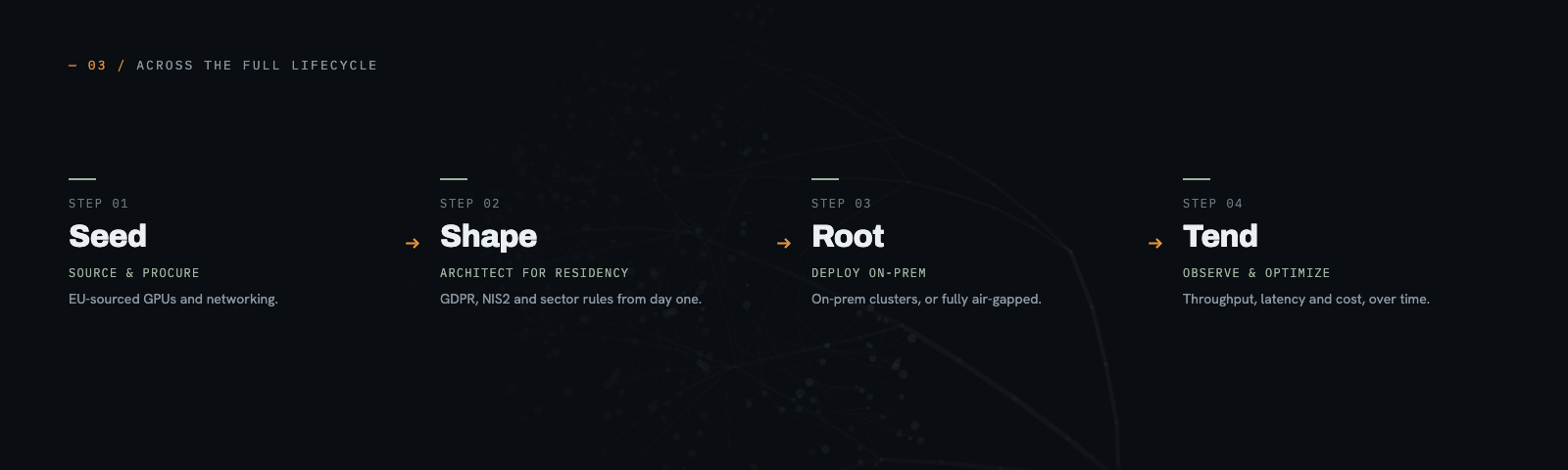
If your organization needs AI that performs at the level your teams expect, while keeping every model, byte of data, and inference call inside EU jurisdiction, or fully offline, that is exactly the infrastructure we build.
Talk to us about your infrastructure.
About the Authors
About Marta Ivanovic
Operations Manager